Phương pháp nghiên cứu trên toàn hệ gen (GWAS)
Thông qua nhiều kết quả nghiên cứu, các nhà khoa học đã xác định chứng nghiện thuốc lá và rượu liên quan tới những gen đặc trưng trong một số loại tế bào thần kinh nhất định. Các tế bào này kích hoạt những tế bào khác gửi tín hiệu hóa học đến não bộ. Khi bị kích thích, trong não bộ con người sẽ có hàng ngàn các phản ứng hóa học diễn ra và rất nhiều chất hóa học chịu trách nhiệm dẫn truyền thông tin trong não bộ. Đó là các chất hóa học tự nhiên tạo điều kiện giao tiếp giữa các tế bào thần kinh, trong đó có norepinephrine và serotonin.
Phương pháp nghiên cứu trên toàn hệ gen (Genome-Wide Association Studies - GWAS) là phương pháp cơ bản để cung cấp cách thức xác định các gen liên quan đến các đặc điểm phức tạp của con người, chẳng hạn như chứng nghiện thuốc lá hoặc uống rượu nhiều. Phương pháp này liên quan đến việc nghiên cứu các biến dị nhiễm sắc thể quen thuộc của nhiều cá thể khác nhau, từ đó xác định mối tương quan của mỗi biến dị với một đặc tính cụ thể. Ví dụ như GWAS thường tập trung xem xét các điểm đa hình các nucleotide đơn (single nucleotide polymorphisms -SNP) nào có quan hệ tương quan tới các triệu chứng bệnh. Trong di truyền y học, SNP là sự thay thế của một nucleotide đơn tại một vị trí cụ thể trong bộ gen có trong một phần đủ lớn của quần thể. Vài năm trở lại đây, vai trò của SNP đã được nhiều nhà khoa học quan tâm và có sự gia tăng số lượng công trình nghiên cứu trong lĩnh vực này
Thông qua GWAS, các nhà nghiên cứu có thể xác định các vùng trong bộ gen đóng vai trò quyết định các đặc điểm cụ thể, so với những cá nhân không biểu hiện đặc điểm đó. Tuy nhiên, phương pháp nghiên cứu trên toàn bộ hệ gen chưa thể cho chúng ta biết đầy đủ về cách các gen ở những vùng đó ảnh hưởng đến một tính trạng hay đặc điểm cụ thể. Bởi vì, những đặc điểm này thường nằm trong vùng ADN không mã hóa của bộ gen. Vì vậy cần những mô hình và phương pháp nghiên cứu chuyên sâu tới vùng ADN không mã hóa này.
SNP xảy ra do sự biến đổi trong trình tự phân tử ADN của các nucleotide A, G, T và C ở một điểm nhất định (hình 1). Mỗi cơ thể có nhiều SNP khác nhau tạo nên một kiểu ADN đặc trưng cho cá thể đó. Chẳng hạn, trình tự ADN của một cá thể nào đó là GCAACGTTA, nhưng ở cá thể khác lại là GCAGCGTTA. Như vậy tại vị trí thứ 4 đã có sự thay đổi và khác nhau ở vị trí này, do đó được gọi là SNP. SNP tồn tại trong gen, nằm ngoài vùng mã hóa. Các nhà khoa học đã xác định được hàng triệu SNP khác nhau; các SNP chỉ có 2 alen (dạng cụ thể của 1 gen có chức năng di truyền nhất định) tạo nên 6 kiểu tổ hợp: A/G, C/ T, A/T, C/G, T/G, A/C. Tỷ lệ đột biến của SNP thấp, khoảng 1/100.000.000.
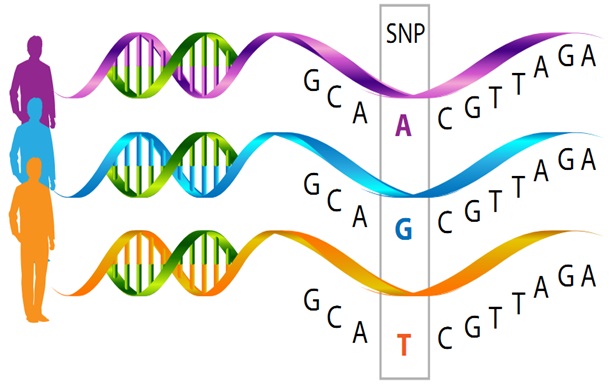
Hình 1. Phương pháp phân tích SNP.
Phát hiện vai trò mới của trình tự ADN không mã hóa
Trình tự ADN không mã hóa là các trình tự ADN đặc biệt của một cá thể và không mang thông tin di truyền mã hóa cho quá trình tổng hợp protein. Theo các nghiên cứu đã được công bố, chỉ 1% gen mang thông tin mã hóa protein, 99% còn lại không mã hóa protein. ADN không mã hóa không mang thông tin dịch mã protein. Các nhà khoa học từng nghĩ rằng, chúng là các ADN rác và không biết mục đích của chúng. Tuy nhiên, các nghiên cứu gần đây đã cung cấp những bằng chứng cho thấy vai trò không thể thiếu của chúng trong hoat động chức năng của tế bào, đặc biệt là chức năng điều khiển hoạt động của gen. Ví dụ như ADN không mã hóa chứa những đoạn trình tự đóng vai trò như những yếu tố điều hòa, xác định thời điểm và nơi mà các gen hoạt động và kết thúc. Hay nói cách khác, chúng cung cấp các điểm, vị trí để các protein chuyên biệt thực hiện chức năng hoạt hóa hoặc ức chế biểu hiện của gen mã hóa tổng hợp ra các protein.
Một số yếu tố cấu trúc của nhiễm sắc thể cũng có chứa ADN không mã hóa. Ví dụ, các đoạn trình tự ADN không mã hóa lặp lại ở vị trí cuối của nhiễm sắc thể hình thành các telomere. Telomere bảo vệ các điểm cuối của nhiễm sắc thể không bị ngắn đi trong suốt quá trình sao chép vật liệu di truyền (hình 2).
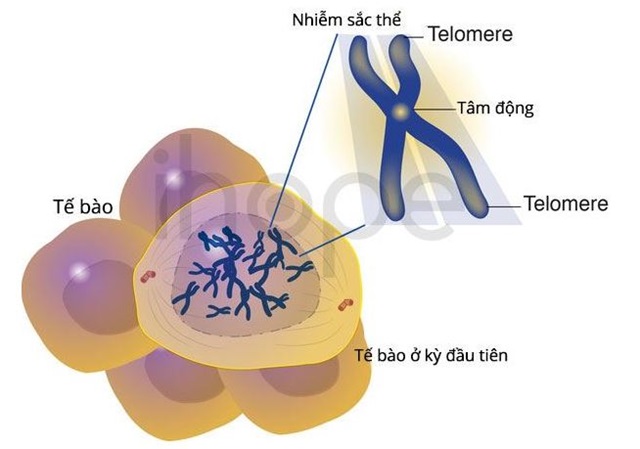
Hình 2. Sự hình thành các telomere.
Phát hiện mới dựa trên mô hình H-MAGMA
Các nghiên cứu của TS Hyejung Won và cộng sự (UNC) tập trung tìm hiểu những gì đang xảy ra ở những vùng ADN không mã hóa. Gần đây, dựa trên mô hình phân tích đa điểm của GenoMic Annotation (MAGMA), nhóm nghiên cứu đã kết hợp với kỹ thuật gen và biểu sinh thông lượng cao Hi-C, tạo ra mô hình mới H-MAGMA và có những phát hiện sâu hơn về vị trí đặc biệt này của bộ gen.
Mô hình MAGMA ban đầu được phát triển để trích xuất những hiểu biết sinh học từ GWAS bằng cách liên kết các biến thể nguy cơ với gen đồng hợp (là kiểu gen mà cá thể mang 2 alen giống nhau thuộc cùng một gen) của chúng. Nó tổng hợp các liên kết SNP thành các liên kết cấp độ gen trong khi điều chỉnh các yếu tố gây nhiễu như chiều dài gen, tần số alen nhỏ và mật độ gen. Mặc dù MAGMA là một công cụ mạnh mẽ và đã được sử dụng rộng rãi, nhưng vẫn còn những hạn chế. Mô hình H-MAGMA do Hyejung Won và nhóm nghiên cứu đề xuất đã khắc phục những hạn chế của mô hình MAGMA, thực hiện gán SNP không mã hóa cho các gen ghép của chúng dựa trên tương tác phạm vi dài trong các mô liên quan đến triệu chứng bệnh được đo bằng Hi-C trên cơ sở lập bản đồ gen. Những kết quả này nhấn mạnh tầm quan trọng của việc sử dụng bằng chứng bộ gen chức năng trong việc chỉ định SNP không mã hóa cho các gen.
Mô hình H-MAGMA đã phát triển dựa trên các tế bào thần kinh dopaminergic - chất dẫn truyền thần kinh và tế bào thần kinh vỏ não. Trên cơ sở đó, mô hình H-MAGMA đã phát hiện ra những minh chứng có giá trị trên GWAS liên quan đến mức độ nặng của hút thuốc, phụ thuộc vào nicotine, cũng như mức độ nặng của việc lạm dụng rượu để xác định các gen liên quan đến từng đặc điểm, tính trạng. Nghiên cứu cũng chỉ ra rằng, các gen liên quan đến việc sử dụng rượu và hút thuốc lá cũng có sự liên quan đến việc lạm dụng các loại chất khác, chẳng hạn như morphin và cocaine. Bằng cách mô tả đặc điểm chức năng sinh học của những gen này, các nhà nghiên cứu có thể xác định cơ chế sinh học tiềm ẩn của chứng nghiện, thậm chí có thể tổng quát được nhiều dạng rối loạn sử dụng chất gây nghiện. Ngoài các loại tế bào thần kinh kích thích khác nhau, Hyejung Won và cộng sự cũng xác nhận các loại tế bào bổ sung, bao gồm glutamatergic vỏ não, tế bào thần kinh dopaminergic não giữa, GABAergic và serotonergic có liên quan đến gen nguy cơ gây ra chứng nghiện.
Với những phát hiện có giá trị này, các nhà nghiên cứu của UNC đã đưa ra những đề xuất cũng như hướng nghiên cứu tiếp theo nhằm tìm ra giải pháp hạn chế việc lạm dụng thuốc lá, rượu bia.
1 Nghiên cứu được công bố trên Tạp chí Molecular Psychiatry số 27, xuất bản ngày 7/7/2022.
TÀI LIỆU THAM KHẢO
1. M. Iskhakova, et al. (2022), “Chromatin architecture in addiction circuitry identifies risk genes and potential biological mechanisms underlying cigarette smoking and alcohol use traits”, Mol Psychiatry, 27, pp.3085-3094, DOI:10.1038/s41380-022-01558-y.
2. H. Won, et al. (2020), “A computational tool (H-MAGMA) for improved prediction of brain-disorder risk genes by incorporating brain chromatin interaction profiles”, Nat Neurosci., 23(4), pp.583-593, DOI:0.1038/s41593-020-0603-0.
Mai Văn Thủy (tổng hợp)