Sự vượt trội và kiến trúc cơ bản của Mô hình ngôn ngữ thị giác
Không giống như các Mô hình thị giác máy tính truyền thống, VLM không bị giới hạn bởi một tập lớp cố định hoặc một nhiệm vụ cụ thể như phân loại (classification) hay nhận diện. Sau khi được huấn luyện với một tập dữ liệu khổng lồ các cặp mô tả cùng hình ảnh hoặc video, VLM có thể được hướng dẫn bằng ngôn ngữ tự nhiên để thực hiện không chỉ các tác vụ thị giác truyền thống mà còn cả các tác vụ tạo sinh như tóm tắt nội dung hay hỏi đáp trực quan.
Hầu hết các VLM tuân theo kiến trúc gồm 3 phần chính:
Bộ mã hóa thị giác: trích xuất các đặc tính thị giác quan trọng như màu sắc, hình dạng và kết cấu từ đầu vào là hình ảnh hoặc video, sau đó chuyển chúng thành một ma trận véc-tơ mà các mô hình học máy có thể xử lý. Các VLM hiện đại hiện tại thường được huấn luyện trên hàng triệu cặp hình ảnh - văn bản, nhờ đó có thể liên kết hình ảnh với ngôn ngữ.
Bộ chiếu: tập hợp các lớp chuyển đổi đầu ra của Bộ mã hóa thị giác thành dạng mà LLM có thể hiểu, thường là các token hình ảnh. Thành phần này có thể đơn giản là một lớp tuyến tính hoặc phức tạp hơn như các lớp chú ý chéo được sử dụng trong Llama 3.2 Vision.
LLM: đóng vai trò như "bộ não ngôn ngữ", giúp nắm bắt ngữ nghĩa và các mối liên kết ngữ cảnh giữa các từ và cụm từ, từ đó đưa ra phản hồi. Đầu ra của LLM có thể là các véc-tơ hoặc văn bản. Bất kỳ LLM nào cũng có thể được sử dụng để xây dựng một VLM. Hiện nay, có hàng trăm biến thể của VLM được tạo ra bằng cách kết hợp nhiều LLM khác nhau với các Bộ mã hóa thị giác.
Huấn luyện Mô hình ngôn ngữ thị giác
Tiền huấn luyện: mục tiêu của giai đoạn này là đồng bộ hóa bộ mã hóa thị giác, bộ chiếu và LLM, giúp chúng có thể “nói chung một ngôn ngữ” khi xử lý đầu vào văn bản và hình ảnh. Quá trình này sử dụng một lượng lớn dữ liệu gồm các cặp văn bản - hình ảnh. Khi ba thành phần này đã được đồng bộ, VLM sẽ tiếp tục giai đoạn tinh chỉnh có giám sát.
Tinh chỉnh có giám sát: ở bước này, VLM được huấn luyện để hiểu cách phản hồi các yêu cầu của người dùng. Dữ liệu đầu vào là tập hợp các câu lệnh mẫu kèm hình ảnh/văn bản và phản hồi mong muốn. Ví dụ, mô hình có thể được yêu cầu mô tả nội dung trong ảnh hoặc đếm số vật thể trong khung hình. Sau giai đoạn này, VLM sẽ học cách diễn giải hình ảnh chính xác hơn và phản hồi phù hợp với ngữ cảnh.
Sau khi được huấn luyện, VLM có thể sử dụng giống như LLM, cho phép người dùng nhập câu lệnh có thể kèm theo hình ảnh. Mô hình sẽ phân tích dữ liệu đầu vào và tạo ra phản hồi dưới dạng văn bản. Thông thường, VLM được triển khai dưới dạng API REST của OpenAI để dễ dàng tích hợp vào các ứng dụng.
Ứng dụng trong nhiều tác vụ kết hợp xử lý ngôn ngữ và hình ảnh
VLM đang nhanh chóng trở thành công cụ hàng đầu trong các tác vụ liên quan đến thị giác máy tính (bảng 1) nhờ vào khả năng linh hoạt và hiểu ngôn ngữ tự nhiên. Chỉ với các câu lệnh bằng văn bản, VLM có thể thực hiện nhiều tác vụ khác nhau như:
Chú thích và mô tả hình ảnh/video: VLM có thể tạo ra các chú thích hoặc mô tả chi tiết về hình ảnh. Bên cạnh đó, mô hình này cũng có thể tóm tắt nội dung của video và các văn bản trên định dạng hình ảnh.
Tạo hình ảnh từ văn bản: VLM có thể tạo ra các hình ảnh từ các câu lệnh văn bản. Một vài công cụ tạo hình ảnh từ văn bản phổ biến hiện nay có thể kể đến DALL-E, Imagen, Midjourney, Stable Diffusion.
Tìm kiếm và truy xuất hình ảnh: dựa trên một câu lệnh văn bản, VLM có khả năng tìm kiếm trong kho dữ liệu hình ảnh và video, từ đó truy xuất hình ảnh hoặc video có liên quan.
Phân đoạn hình ảnh: VLM có thể phân chia một hình ảnh thành các phần dựa trên các đặc điểm không gian đã được học, sau đó tạo ra các mô tả văn bản cho từng phần.
Nhận diện vật thể: VLM có thể nhận diện và phân loại các vật thể trên một hình ảnh và tạo ra các mô tả theo ngữ cảnh như vị trí của vật thể so với các yếu tố trực quan khác.
Hỏi đáp trực quan: với khả năng phân tích trực quan, VLM có thể trả lời các câu hỏi liên quan đến hình ảnh hay video.
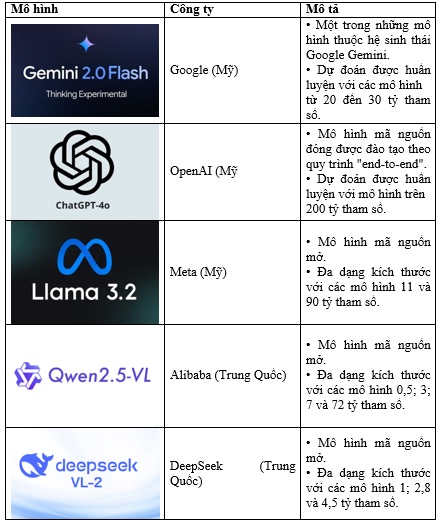
Bảng 1. Một số Mô hình ngôn ngữ thị giác tiên tiến hiện nay.
Tiềm năng ứng dụng và thách thức
Tiềm năng ứng dụng
Trong giáo dục: tạo ra các nội dung và tài liệu học sinh động kết hợp giữa hình ảnh và văn bản, giúp tăng tính tương tác trong học tập và nâng cao trải nghiệm của học viên. Giúp giáo viên và học viên dễ dàng tìm kiếm các tài liệu học tập phù hợp với đa dạng định dạng (hình ảnh, sơ đồ, video), giúp cải thiện hiệu quả học tập.
Đối với thương mại điện tử: ngoài mô tả bằng văn bản, người mua có thể tìm kiếm sản phẩm bằng hình ảnh. Tính năng này hỗ trợ người mua dễ dàng tìm kiếm sản phẩm cụ thể hay điều hướng người mua đến danh mục sản phẩm phù hợp hoặc liên quan. Tự động tạo mô tả chi tiết sản phẩm dựa trên hình ảnh, giúp tiết kiệm thời gian và chi phí nhân lực cho doanh nghiệp.
Trong y tế: hỗ trợ các bác sỹ phân tích ảnh chụp X-quang, MRI, CT, kết hợp với hồ sơ bệnh nhân và các ghi chú lâm sàng khác để đưa ra những chẩn đoán chính xác và phác đồ điều trị thích hợp. Tích hợp các dữ liệu hình ảnh y tế và văn bản để tạo các báo cáo và hồ sơ y tế, hỗ trợ trong việc theo dõi tiền sử bệnh nhân.
Trong robot hình người: giúp robot nhận diện và định vị các vật thể xung quanh, từ đó thực hiện các nhiệm vụ cụ thể như thu thập đồ vật hoặc di chuyển đến vị trí yêu cầu một cách chính xác. Các VLM có thể xử lý cả hình ảnh và văn bản, cho phép robot hình người "nhìn" và "nghe" các câu lệnh hoặc chỉ dẫn cụ thể.
Trong sản xuất: phát hiện lỗi của sản phẩm dựa trên phân tích hình ảnh. Phát hiện các mối nguy hiểm về an toàn trong môi trường sản xuất dựa trên phân tích video theo thời gian thực.
Thách thức
Tính thiên kiến: các phản hồi một VLM đưa ra có thể mang tính thiên kiến vì bị ảnh hưởng bởi những dữ liệu được sử dụng để huấn luyện mô hình. Tuy vậy, sử dụng các nguồn dữ liệu huấn luyện đa dạng cùng việc kết hợp giám sát của con người trong suốt quá trình có thể giúp giảm thiểu tính thiên kiến của mô hình.
Chi phí và độ phức tạp mô hình: VLM và LLM đều là những mô hình phức tạp, việc kết hợp giữa hai mô hình này sẽ làm tăng thêm tính phức tạp của chúng. Việc kết hợp giữa hai mô hình này cũng yêu cầu nhiều tài nguyên và chi phí huấn luyện hơn, làm cho việc triển khai và mở rộng VLM trên quy mô lớn khó khăn hơn và cần nhiều đầu tư về nguồn lực.
Khả năng tổng quát và thích ứng: là việc mô hình có thể áp dụng được kiến thức đã được huấn luyện trên những dữ liệu cũ vào các tình huống mới hoặc không quen thuộc. Đối với những dữ liệu mới và chưa từng thấy trước đây, các mô hình VLM có thể gặp khó khăn trong việc thích ứng và đưa ra những dự đoán chính xác. Một tập dữ liệu có chứa những trường hợp ngoại lệ và áp dụng zero-shot learning có thể giúp các mô hình VLM thích nghi với các khái niệm mới.
Tính ảo giác: cũng giống như các mô hình AI khác, mô hình VLM cũng có thể gây ra hiện tượng "ảo giác" khi tạo ra thông tin không chính xác hoặc không tồn tại, nhưng lại diễn giải như đó là sự thật. Để hạn chế tính ảo giác và đảm bảo đưa ra những thông tin chính xác, việc xác thực lại các kết quả đưa ra của mô hình là yếu tố quan trọng.
Nguyễn Thị Hiền (tổng hợp từ: https://vinbigdata.com)